自從之前安裝好R上的 rJava 和 RJDBC 套件(這篇:R 上安裝 RJDBC 和 rJava 的除錯),就應該可以借回那本書繼續學習R上連結用MySQL的例子。加上最近又想繼續股票短線的技術分析模型,希望將計算後的指標輸出到 Excel可以接手做試驗的形式,於是這幾天都在對著RStudio。股票方面思考過匯出怎樣的資料和格式才方便Excel處理,整理過之前的幾段Scirpt, 但想要的結果仍在做回溯測試中。而SQL的例子就可以告一段落了。
這個例子中的"Sakila"數據是MySQL 提供的樣本,假設一間DVD租售店的營運,數據庫的結構參考: https://dev.mysql.com/doc/sakila/en/sakila-structure.html。這個教學例子是利用顧客的租借記錄,以及電影的類別、分級等資料,製做一個推薦系統,為顧客推薦他可能有興趣的電影。一個方法是計算利用顧客的借閱記錄計算顧客間的相似性,這個就是下面的例子。書中也提及另一個方法是利用被電影被借閱的記錄計算電影間的相似性。實際上,更好的算法應該還要考慮在新的顧客或電影時如何更新推薦。
2016年12月29日 星期四
2016年12月21日 星期三
[Java/Excel] 用 Eratosthenes Sieve (和 Euler Sieve) 求質數表,以及因式分解
上星期想破頭的數論之後,這星期都在看質數相關的Coding。
雖然最終要求的是:$ x^2+y^2 =N $ 的整數解,過程中也回顧了 Eratosthenes's Sieve 求質數表,和用質數表做因式分解 的方法。所用的語言方面,一個目標是自己想要熟習,而且資源又常見的Java;另一個是如果自己在中學時期想這樣做的話,應該會用到的VBA。
Java的例子不少,但試過才知道即使實現的是同一套算法,效率也可以有很大差別。從前只知道應用數學中會看一套算法的Big O去比較時間複雜度,但原來實踐起來用什麼語言、什麼變數物件,結果用什麼什麼形式去表現⋯⋯都會大大影響速度。就是為了找出實際運行得更快的寫法,就一頭栽到這個質數的做法上。雖然一開始時用LinkedList、Map等寫法真的很方便理解,但之後還是儘量換成基本的陣列。
下面這樣的Java寫的 Eratosthenes Sieve 求 一億($10^8$)之內的質數,大約是10秒。如果不計最後一個for loop用來製作傳回值的LinkedList<Integer>的話,主流程大約4秒。不過要求更大的質數,應該還要考慮該程式對使用整數的上限(int: [-2,147,483,648, 2,147,483,647]),大數字在記憶體的儲存方法,整數表的儲存方法等。很多事情都是這樣吧,開始時只要求做到是容易的,但要追求深究下去就會困難⋯⋯
最後還有兩個方法是Modified Eratosthenes Sieve 和 Euler Sieve,都是理論上應該更有效率的算法,不過實踐起來還是達不到應有的分別,要怪我對如何更好地寫代碼還是不熟識吧。 Eratosthenes Sieve的Modification的想法是一開始就不考慮2和3的倍數,只看6k+1和6k+5的情況。至於 Euler Sieve 是改善Eratosthenes Sieve中一個合成數會重覆被質數篩去而浪費的時間,例如,合成數6 會在篩選質數 2和3 的倍數時重覆考慮。理想中Eratosthenes Sieve的時間複雜度是 O( n*log(log(n)) ),而Euler Sieve的時間複雜度是O(n)。實測中,同樣求一億($10^8$)之內的質數,大約是2-3秒的時間。
雖然最終要求的是:$ x^2+y^2 =N $ 的整數解,過程中也回顧了 Eratosthenes's Sieve 求質數表,和用質數表做因式分解 的方法。所用的語言方面,一個目標是自己想要熟習,而且資源又常見的Java;另一個是如果自己在中學時期想這樣做的話,應該會用到的VBA。
Java的例子不少,但試過才知道即使實現的是同一套算法,效率也可以有很大差別。從前只知道應用數學中會看一套算法的Big O去比較時間複雜度,但原來實踐起來用什麼語言、什麼變數物件,結果用什麼什麼形式去表現⋯⋯都會大大影響速度。就是為了找出實際運行得更快的寫法,就一頭栽到這個質數的做法上。雖然一開始時用LinkedList、Map等寫法真的很方便理解,但之後還是儘量換成基本的陣列。
下面這樣的Java寫的 Eratosthenes Sieve 求 一億($10^8$)之內的質數,大約是10秒。如果不計最後一個for loop用來製作傳回值的LinkedList<Integer>的話,主流程大約4秒。不過要求更大的質數,應該還要考慮該程式對使用整數的上限(int: [-2,147,483,648, 2,147,483,647]),大數字在記憶體的儲存方法,整數表的儲存方法等。很多事情都是這樣吧,開始時只要求做到是容易的,但要追求深究下去就會困難⋯⋯
最後還有兩個方法是Modified Eratosthenes Sieve 和 Euler Sieve,都是理論上應該更有效率的算法,不過實踐起來還是達不到應有的分別,要怪我對如何更好地寫代碼還是不熟識吧。 Eratosthenes Sieve的Modification的想法是一開始就不考慮2和3的倍數,只看6k+1和6k+5的情況。至於 Euler Sieve 是改善Eratosthenes Sieve中一個合成數會重覆被質數篩去而浪費的時間,例如,合成數6 會在篩選質數 2和3 的倍數時重覆考慮。理想中Eratosthenes Sieve的時間複雜度是 O( n*log(log(n)) ),而Euler Sieve的時間複雜度是O(n)。實測中,同樣求一億($10^8$)之內的質數,大約是2-3秒的時間。
2016年12月12日 星期一
[Math] 由3個連續數組成的平方和組合 - Consecutive Triple, which are simultaneously sum of 2 squares
前言
先看一下以下數式,有某些數字可以寫成2個平方的和。$
00 = 0^2 + 0^2\\
01 = 1^2 + 0^2\\
02 = 1^2 + 1^2\\
03 = ---..... =3;\\
04 = 2^2 + 0^2\\
05 = 2^2 + 1^2\\
06 = ---...... =2*3\\
07 = ---...... =7\\
08 = 2^2 + 2^2\\
09 = 3^2 + 0^2\\
10 = 3^2 + 1^2 \\
11 = ---..... =11 \\
12 = ---..... =2*2*2*3\\
13 = 3^2 + 2^2\\
14 = ---..... =2*7\\
15 = ---..... =3*5\\
16 = 4^2 + 0^2\\
17 = 4^2 + 1^2\\
18 = 3^2 + 3^2\\
19 = ---..... =19\\
20 = 4^2 + 2^2\\
......\\
$
$
25 = 4^2 + 3^2 = 5^2 + 0^2\\
......\\
65 = 7^2 + 4^2 = 8^2 + 1^2\\
......\\
$
- 某些數字可以寫成2個平方的和,某些則不能,而要寫成更多個平方的和。公元3世紀時的Diophantus提出「是否每一個正整數都是四個平方數之和」的問題。更一般性的問題是 18世紀時的Waring’s problem,他猜想:「對於每個非1的正整數 k,皆存在正整數 g(k),使得每個正整數都可以表示為至多g(k)個k次方數之和。」Diophantus的提問即是當 k=2 的情況 。Lagrange證明了這個情況是 g(2) = 4:任何一個正整數可用4個平方數之和得出。
(e.g. $60=7^2+3^2+1^2+1^2$)
其他情況的證明有 Arthur Wieferich:g(3)=9。Joseph Liouville:g(4)=19。陳景潤:g(5)=37。任何一個正整數可用9個立方數之和、或19個4次方數之和、或37個5次方數之和得出。
- 而對於一個正整數是否可以寫成兩個平方數之和。
首先可留意到上面3、7、11、15、19.... 這些 $(4k+3)$ 的單數項都不能表達成兩個平方數之和。要將一個單數寫成兩個平方之和,兩數必定是一正一負,寫成: $(2k+1)^2 + (2k)^2 = 4(2k^2 + k) + 1$。Fermat首先證明對於單數的質數,可以寫成 (4k+1) 是該數能否寫成兩個平方數之和的充分及必要的條件。 然後,再留意上面寫不到平方和的例子,質因數分解中都出現單數次(4k+3) 形式的質因數項。Euler 證明出以下的條件:
"A number N is expressible as a sum of 2 squares if and only if in the prime factorization of N, every prime of the form (4k+3) occurs an even number of times! "$$N = {2}^{a_0} {p_1}^{2a_1}...{p_r}^{2a_r} {q_1}^{b_1}...{q_s}^{b_s}$$
於是,我們可以分辨出一個數是否可以寫成兩個平方之和。
2016年12月11日 星期日
2016年秋 - 一個月的外地工作:印度班加羅爾(Bangalore)-食
今年終於成行到印度的Bangalore的部門,訓練這邊的同事接手部份工作。居住和工作的地方都位於Bellandur區,附近都是辦公室的地區,有幾個科學園區、商業園區、工業園區,這些有點像香港的科學園般,我們公司就用到園區內某大樓的數層作辦公室。
如果在Google上尋找,你會看到Bengaluru這個名字,話說在2014年正式改名為Bengaluru之前這裡一直是稱為Bangalore,平時生活基本上都是見習慣用Bangalore的。而印度政府早在20年代至今一直有將一些城市改名,例如Bangalore附近的Mysore(舊)改名為Mysuru(新)、旅遊地點Ooty(習慣)與Udhagamandalam(正式),我一直認知的交易所Bombay(舊)原來即是Mumbai(新)。在找資料時記得有時用舊名更方便。
雖然今次出差有一個月的日子,不過星期一至五專心工作,自己也帶了電腦、書和電路板繼續項目,都是周未才會外出。除了Bellandur附近的街道,也就去了Bangalore的市中心,跟當地團去參觀Bangalore附近的城市Mysore。今次正正經歷到 8/11 印度總理 宣佈大額紙幣 500和1000盧比 即晚起停止流通,逼使國民存回銀行和申報。他目的是打擊國民瞞稅和權貴舞弊而藏在家中的"黑錢",事前未有透露計劃,由宣佈到實行只有4小時。Mysore之行正好在廢鈔令之後的周未,在擔心缺錢下,由包車也改為跟團,總算遊了一趟。
在印度一個月的「食、住、行」方面的體驗,「食」留下的照片最易整理,就先記錄食的部份。還有很多沒有拍下的就留在印象中,有拍照的如下:
 Dosa:Dosa有兩種,比較喜歡煎成脆身的Dosa,內裡可以加入餡料,再沾些醬汁。圖中是綠色帶薄荷/香草的Mint Chutney,一向比較喜歡。其他地方試過最喜歡那種白色不帶辣的Coconut Chutney,另一款辣的甘醬就不太合口味了。
Dosa:Dosa有兩種,比較喜歡煎成脆身的Dosa,內裡可以加入餡料,再沾些醬汁。圖中是綠色帶薄荷/香草的Mint Chutney,一向比較喜歡。其他地方試過最喜歡那種白色不帶辣的Coconut Chutney,另一款辣的甘醬就不太合口味了。



如果在Google上尋找,你會看到Bengaluru這個名字,話說在2014年正式改名為Bengaluru之前這裡一直是稱為Bangalore,平時生活基本上都是見習慣用Bangalore的。而印度政府早在20年代至今一直有將一些城市改名,例如Bangalore附近的Mysore(舊)改名為Mysuru(新)、旅遊地點Ooty(習慣)與Udhagamandalam(正式),我一直認知的交易所Bombay(舊)原來即是Mumbai(新)。在找資料時記得有時用舊名更方便。
雖然今次出差有一個月的日子,不過星期一至五專心工作,自己也帶了電腦、書和電路板繼續項目,都是周未才會外出。除了Bellandur附近的街道,也就去了Bangalore的市中心,跟當地團去參觀Bangalore附近的城市Mysore。今次正正經歷到 8/11 印度總理 宣佈大額紙幣 500和1000盧比 即晚起停止流通,逼使國民存回銀行和申報。他目的是打擊國民瞞稅和權貴舞弊而藏在家中的"黑錢",事前未有透露計劃,由宣佈到實行只有4小時。Mysore之行正好在廢鈔令之後的周未,在擔心缺錢下,由包車也改為跟團,總算遊了一趟。
在印度一個月的「食、住、行」方面的體驗,「食」留下的照片最易整理,就先記錄食的部份。還有很多沒有拍下的就留在印象中,有拍照的如下:
小食
公司園區外有一堆流動小食檔,由下午4-5時開檔至凌晨。賣茶或咖啡(和煙)的檔主第二朝一早就已經見佢開檔,仲會帶住脆口的零食。


2016年12月4日 星期日
Android + Arduino 小車的手機藍牙遙控計劃
對於手機的Android Apps今次是作為初學者的第一個項目。但不枉我在這次印度公幹期間,電腦之外,我都執了幾件零件和書。在印度試好了如何在Android上用藍牙連接Arduino,簡單的按鍵去傳送方向指令(數字),和預備日後作其他用途的顯示和輸入介面。詳細的檔案己經放到下面的dropbox link。
Arduino Sketch: https://dl.dropboxusercontent.com/u/71621110/Blogger/Sketch_CarBT.ino
Android Project: https://dl.dropboxusercontent.com/u/71621110/Blogger/myFirstBluetoothApp.zip
連接藍牙到Arduino時要像以下般連接,藍牙模組會直播接連到板子上的TX,RX 腳位。當Arduino開始"setup()"時除了設定相關腳位的pinMode外,也需設定Serial的通訊。之後的程式上就可以像Serial 通訊般互傳指令。而Serial Rate 要跟自己藍牙模組的Baud Rate 相同,才可以在同一頻率下理解訊息。之前在電腦上搜尋這藍牙時,確定自己用的是HC-05的藍牙組件。HC-05出廠設定是rate=9600,配對密碼1234。
Arduino Sketch: https://dl.dropboxusercontent.com/u/71621110/Blogger/Sketch_CarBT.ino
Android Project: https://dl.dropboxusercontent.com/u/71621110/Blogger/myFirstBluetoothApp.zip
Arduino
首先,Arduino 的Sketch中,令小車移動的指令是連接L298D的4個腳位控制個馬達的正轉反轉和速度。先把向前向後轉左轉右等指令包裝成forward()、backward()、left()、right()、brake()等指令:int Left_motor_go=8; //左馬達前進(IN1)
int Left_motor_back=9; //左馬達後退(IN2)
int Right_motor_go=10; // 右馬達前進(IN3)
int Right_motor_back=11; // 右馬達後退(IN4)
void forward() // 前進
{
digitalWrite(Right_motor_go,HIGH); // 右馬達前進
digitalWrite(Right_motor_back,LOW);
digitalWrite(Left_motor_go,LOW); // 左馬達前進
digitalWrite(Left_motor_back,HIGH);
analogWrite(Right_motor_go,200);
analogWrite(Right_motor_back,0);
analogWrite(Left_motor_go,0);
analogWrite(Left_motor_back,200);
}連接藍牙到Arduino時要像以下般連接,藍牙模組會直播接連到板子上的TX,RX 腳位。當Arduino開始"setup()"時除了設定相關腳位的pinMode外,也需設定Serial的通訊。之後的程式上就可以像Serial 通訊般互傳指令。而Serial Rate 要跟自己藍牙模組的Baud Rate 相同,才可以在同一頻率下理解訊息。之前在電腦上搜尋這藍牙時,確定自己用的是HC-05的藍牙組件。HC-05出廠設定是rate=9600,配對密碼1234。
Bluetooth's TX <--> Arduino's RX
Bluetooth's RX <--> Arduino's TX
Bluetooth's GND <--> Arduino's GND
Bluetooth's VCC <--> Arduino's 5V
2016年11月21日 星期一
[R] R 上安裝 RJDBC 和 rJava 的除錯
話說早前有關R找到本不錯的教學書,試過模仿它測試股票投資策略的那一章後,正要嘗試 R與MySQL的連接,但想從書中的RODBC Library改為用RJDBC Library。當時已經安裝好MySQL,MySQL Workbench,下載了JDBC Connector 的 jar 檔,在 R 上安裝了 RJDBC Library,但要使用時卻一直在報錯而用不到。在印度的最後幾天,想起再繼續 R 的項目,跟 rJava 的設定糾纏了幾小時,在最氣餒的時候終於有了突破,一步步順利的通關。
原本報錯的情況,是在載入 library(RJDBC) 的時候,回報說在調用 library(rJava) 的 .jinit() 時出錯,找不到要用的JVM。
R> .jinit()
JavaVM: requested Java version ((null)) not available. Using Java at "" instead.
JavaVM: Failed to load JVM: /bundle/Libraries/libserver.dylib
JavaVM FATAL: Failed to load the jvm library.
Error in .jinit() : JNI_GetCreatedJavaVMs returned -1
之後己經事前準備好的:
1. R 和 Java 是本身己經在用的,本身分別搭配著 R Studio 和 Eclipse 使用

2. 安裝好MySQL 和 MySQL Workbench。記住連接用的user和pwd
(下載:http://dev.mysql.com/downloads/mysql/;http://dev.mysql.com/downloads/workbench/)
3. 下載JDBC Connector 的jar檔:
(下載:http://dev.mysql.com/downloads/connector/j/)
2016年10月16日 星期日
Arduino 淘寶小車 - 焊接/使用CH341的Driver/功能測試
從Arduino的Starter Kit之後,在淘寶上買了一架Arduino的小車,大概兩天便有貨到手了。這個標榜從做中學的科教玩具,到貨時有一塊Arduino底板,轉接板的印刷電路板(PCB),和將會安裝上面的電子零件,以及組裝小車所需的零件等。大約200港幣,全套包括循跡、紅外線/超音波的避障、紅外線/藍牙的遙控。



焊接
因為那份轉接板是需要把零件遂件焊接的。為此先到鴨寮街買了一支3x元40W的焊機,試過後有時見太熱也會令底板變色,也怕燒壞底板。原來焊頭有不同的輸出功率和溫度,30W的大概已經夠用,高溫和貴點的可以換不同焊頭,可以作刻劃之用,不過也用不著。選購焊錫的過程中會經常見到松香的出現。錫作為焊料,松香作為助焊劑,對焊接有幫助,不過也不是必須吧。建議買一支低功率的焊機,包裝內就連少量焊料的那種。焊接時所有IC先不要安裝到插槽上。
Arduino 的 Starter-Kit Project 2
旅行前完成了Starter Kit 後半的項目。最感興趣的是電容的實驗,當中重要部份是電子方面的原理。Processing的實驗也按步驟的做完,但這個Processing應該有更大的發展空間。有過之前的基本了解,並不難實踐以下的項目。然後也決定跟著Starter Kit做完一次之後,要用組裝一輛玩具車作為下一個學習項目。現在就先補充Starter Kit的後半部:
Project 06
蜂鳴器(Piezo)的使用,可以用tone() function 去設定輸出的音調。有點類似analogWrite() 的PWM輸出般並不是單純的 High/Low 電位,但不同的是tone()改變的是一組訊號的Period長度,也即是改變Frequency。而duty cycle永遠是50%。analogWrite()的PWM是透過固定Period中0%-100%的duty cycle去模擬類比輸出。
Project 06
蜂鳴器(Piezo)的使用,可以用tone() function 去設定輸出的音調。有點類似analogWrite() 的PWM輸出般並不是單純的 High/Low 電位,但不同的是tone()改變的是一組訊號的Period長度,也即是改變Frequency。而duty cycle永遠是50%。analogWrite()的PWM是透過固定Period中0%-100%的duty cycle去模擬類比輸出。
2016年10月2日 星期日
[R] 閱後測試-R語言與股票市場的預測
原來上水圖書館的電腦類書有不少我想要的題目,打算去找點數學的書,結果卻捧了一堆電腦程序的書回來。
《巨量資料的第一步-R語言與商業應用》
《實戰Java-9個別具特色的實作經驗》
《Arduino錦囊妙計》
《Raspberry Pi 機器人自造專案》

這本學習R的書,算是我看過的R中文書當中很好的一本,特別是案例的部份的學習價值就很高。基本內容都有提及一些我不熟悉的。例如時間和時間序列的類型、資料連接SQL資料庫、處理遺留數據等。
上月初,周末加班時就帶著電腦和書,在坐車時跟著書去嘗試。誰知把書放在椅背休息一下,落車時就忘了帶走。好在一星期後發現有人已經代為把書還了圖書館,感謝這個好心人。
首先跟著這本書試的是這一章「股票市場的預測」。 它是用quandmod套件中的getSymbols()功能獲得xts時間序列類型的股價資訊。建立一個自行定義的回報觀察值去衡量價格變動,再用常見的技術分析指標作變數,建立決策樹Decision Tree的模型。最後評價模型的預測誤準確度。
《巨量資料的第一步-R語言與商業應用》
《實戰Java-9個別具特色的實作經驗》
《Arduino錦囊妙計》
《Raspberry Pi 機器人自造專案》

這本學習R的書,算是我看過的R中文書當中很好的一本,特別是案例的部份的學習價值就很高。基本內容都有提及一些我不熟悉的。例如時間和時間序列的類型、資料連接SQL資料庫、處理遺留數據等。
上月初,周末加班時就帶著電腦和書,在坐車時跟著書去嘗試。誰知把書放在椅背休息一下,落車時就忘了帶走。好在一星期後發現有人已經代為把書還了圖書館,感謝這個好心人。
首先跟著這本書試的是這一章「股票市場的預測」。 它是用quandmod套件中的getSymbols()功能獲得xts時間序列類型的股價資訊。建立一個自行定義的回報觀察值去衡量價格變動,再用常見的技術分析指標作變數,建立決策樹Decision Tree的模型。最後評價模型的預測誤準確度。
2016年8月29日 星期一
2016年夏 - 伴隨義工工作營體驗的-羅馬假期「Camp8」
經過上年的柬埔寨工作營和今年的意大利工作營,我想下年應該不會再參加這類義工旅行了。旅行完的時候有那種『已經足夠了』的感覺。大概之後更想要自主度更高,不再是參加者的身份去做事。
今次乘搭的是俄羅斯航空旗下的Aeroflot,又是Boeing轉Airbus的兩程機,全程17小時(連2小時莫斯科轉機),向西飛,算有點適應到這種長途航程。時差方面大概因為要生理時鐘推遲是比較容易。打著草稿的這一刻在莫斯科往羅馬的機上,意大利下午六點半大約是香港晚上十點幾,還未算很眼訓。第一程機雖然要9小時,但在機上的兩餐和一套「死侍」打發時間,換上提供的拖鞋眼罩也可以睡一睡,時間還算好過。在莫斯科等轉機時打算放適量歐元進銀包,才發覺自己沒有帶那裝錢的信封,只有等到羅馬時提取那大背包中的50歐羅.....第二班機的登機閘口從29號轉到了28號,之前沒有留意到通知,一直在29號閘口前等候上機,突然看到電子板的登機提示的時候還有點猶豫,還好就在28號閘口向準備上機的職員問過,就被指示上機了。人未到埗,但在機上看風景,己經感到高空的景色很不一樣,香港有的是城市大厦,尚記得到柬埔寨的河岸,中國的黃土山地;歐洲就比較有印象中的小鎮的面貌,大片的農地原來也和稻田看起來起不一樣。


今次乘搭的是俄羅斯航空旗下的Aeroflot,又是Boeing轉Airbus的兩程機,全程17小時(連2小時莫斯科轉機),向西飛,算有點適應到這種長途航程。時差方面大概因為要生理時鐘推遲是比較容易。打著草稿的這一刻在莫斯科往羅馬的機上,意大利下午六點半大約是香港晚上十點幾,還未算很眼訓。第一程機雖然要9小時,但在機上的兩餐和一套「死侍」打發時間,換上提供的拖鞋眼罩也可以睡一睡,時間還算好過。在莫斯科等轉機時打算放適量歐元進銀包,才發覺自己沒有帶那裝錢的信封,只有等到羅馬時提取那大背包中的50歐羅.....第二班機的登機閘口從29號轉到了28號,之前沒有留意到通知,一直在29號閘口前等候上機,突然看到電子板的登機提示的時候還有點猶豫,還好就在28號閘口向準備上機的職員問過,就被指示上機了。人未到埗,但在機上看風景,己經感到高空的景色很不一樣,香港有的是城市大厦,尚記得到柬埔寨的河岸,中國的黃土山地;歐洲就比較有印象中的小鎮的面貌,大片的農地原來也和稻田看起來起不一樣。


2016年8月7日 星期日
[Excel] 偷看加密的VBA Project Code
因為剛剛放假去了一趟意大利旅遊而沒有更新。回到香港已經兩個星期了,本來打算回來就寫這次的遊記,但才寫到第2天的事,很多都還在整理當中。回港當日一下機就帶著行李直接回Office,不過那星期就在工作上遇到一個特別的發現,值得先記下來充撐充撐⋯⋯話說之前一項專案找了 IT Team寫了一個Excel的工具來做一項數據處理的工序。最近隨著這項目的更新,我們需要另外加入新的運算程序。在同事研究該怎樣做的時候,發現了原來可以輕易破解加密了的Excel VBA Project。就算無意自己去改動IT的出品,對「原來有這辦法」就感到很有趣。日後也是一個好機會去了解下別人的專業角度如何寫Code。
大致上:這方法是用十六進制編輯器-Hex Editor 去打開檔案,找尋並修改檔案中特定的識別字串,就可在打開檔案時除掉加密保護。(這方法是試在辦公室的Window機Office2013。而現在用自家電腦準備以下圖片時知道,Mac機的Office 2011在打開最後那個修改過的檔案時,有不同的處理,所以偷看不到。)



後話:在嘗試這方法時,也想起的當年的PC遊戲-三國志曹操傳,就有使用十六進制編輯器的修改法。
大致上:這方法是用十六進制編輯器-Hex Editor 去打開檔案,找尋並修改檔案中特定的識別字串,就可在打開檔案時除掉加密保護。(這方法是試在辦公室的Window機Office2013。而現在用自家電腦準備以下圖片時知道,Mac機的Office 2011在打開最後那個修改過的檔案時,有不同的處理,所以偷看不到。)
- 常見帶Macro的Excel 會存成 xls 或 xlsm 副檔名的檔案,而這方法用在xls檔上。因為我手上的是xlsm,所以要做一個另存新檔的步驟,存成xls檔。

- 用Hex Editor打開檔案,若是自家電腦可以找Notepad++的外掛,工作的電腦可以抓網上的Online Hex Editor (如 https://hexed.it/)。找尋"DBP"並修改為"DBx"。然後匯出檔案。

- 這時打開剛修改過的檔案,過程中會出現錯誤訊息,可以選擇略過錯誤。然後進入VB Editor,會發現已經可以檢視程式碼(Office 2011只能選擇"開啟並修復",打開後Module部份不見了)。這時最好也重新設定/解除VBA Project的加密,並另行存檔。

後話:在嘗試這方法時,也想起的當年的PC遊戲-三國志曹操傳,就有使用十六進制編輯器的修改法。
2016年7月6日 星期三
「我」的主題是什麼?
我應該定為這個Blog一個主題嗎?
加了『連結清單』,暫時將所有貼文加入「SCIENCE」、「TRAVEL」、或「OTHER」的標籤作為分類。(方法見於後記。)當初開始寫了幾篇筆記後,也有看其他Blog的設計,想參考哪些是我喜歡和可以仿效。我喜歡的多數是外觀比較簡單,方便閱讀的那種。所以一開始用基本樣式,沒有想放太多工具。開始時就想以數學、行山、閱讀為主題,加上任何個人感想的文字雜記。不過當初2012年只有記過一篇行山,然後2013年多數的都只是有把喜歡的章節抄錄下來(當時有練習打字的目標),內容不多,就未有分類的需要。到今年再次動手,才改變一下目標:練習,決心要定期交貨,就什麼都寫吧。雖然自己能寫的都大概離不開以上所選,不過想到寫作的練習比主題重要,寫-就對了。寫過十多篇後有想過分類,原本有擔心改動範本樣式會影響之前加入HTML中的 JS(Latex, Google Analytic)Library ,到找到方法後就知沒有影響。反而問題是要定怎樣的分類才是我想要的?
回到六月初,去了一個 CMX Hong Kong 在觀塘The Wave舉辦的網上社群營運的分享會。以旅遊為主題,邀請了幾位旅遊攝影、寫作的達人,以及NGO、Startup的創辦人來分享他們如何經營社群。很多資訊他們己經後製成圖片放到FB專頁:https://www.facebook.com/groups/cmxhk 。記得開始時一個位嘉賓先講到定義社群,社群的形成是基於共同興趣、話題的團體。當日其中一個感受就是不能先把專頁看成宣傳平台。內容有<半個旅遊記者的故事>的網主Daniel分享如何選擇題材才吸引到讀者:一些特別的題目如巴士到越南、自行出書的經過、生活事件去整造親切感。攝影方面有旅遊攝影主題的Henry 從攝影 -> 旅遊 -> 為報紙寫旅遊稿 -> <旅・攝>專頁的經營,過程中所需和學習到的知識技能[段落之後加圖]。Nat and Hiro 的Blogger和專頁一開始是分享自己環遊世界的經過 -> 線下活動維繫 -> 旅遊文章 -> 產品宣傳項目 -> 開團。我就幾同意這樣的專頁定位:『整造一個社群平台,而不只是單向的推銷』。
 |
| 要掌握的能力有很多 |
 |
| 為每個地方寫的一段簡單的介紹,應該是起碼要做到最的吧 |
2016年7月1日 星期五
尋花路上 - 九龍坑山上的野百合
網上看到最近是野百合開花的時間,花期只有7-10天,報導中介紹的都是在300米以上的地方,九龍坑山也是其中一個報導的地方。這座山因為位處大埔,已經是我行慣行熟的一個假日去處。記得幾年前走到山頂,穿過路邊的草叢,才找到代表最高點的標高柱,對那兒的一朵野百合特別有印象。野百合淡黃色的花瓣張得很大,只是當時卻盛放在隱蔽的地方。但與周圍的植物相比,一定會被它吸引注意。之後幾年來經常走上九龍坑山,讓自己流流汗和呼吸下自然的空氣,但每次上來都未曾再見到它。今個周未起行的目的就是要再上來看一看山頂的野百合。
 |
| 落山時回望的野百合 |
2016年6月28日 星期二
Office Life - 外賣膠飯盒之二 - 選擇與行動
公司的早餐當中,我最常選的是湯粉麵餐,最近打算準備一個最適合自己早餐習慣的『飯盒』,做多一步然後每天可以安心地外賣早餐。不過一款設計要兼顧港式飲食習慣,對一般外賣盒是有難度的。例如相對便當飯盒,盛湯麵的就需要耐熱和高身才不易倒瀉之前在思考一般飯盒的設計時,就感受這個困難:一款飯盒的設計很難兼顧所有用使用情況。市面上很多環保餐具器皿其實都只有它設計的特定用途才會感到最有效用,不然使用上的不便反為是障礙/挑戰。對於我這種長期光顧一間Canteen的使用者,我的出發點是先參考它本身提供的外賣器皿。之前有把這些外賣碗留起來研究(?),主要有一大一小兩款外賣碗,大的用於湯麵餐,小的用在粥和炒粉麵。

自己一直對有種附手柄和蓋的瓷碗有點興趣,而某日行過LOG-ON看到這款微波爐用的膠碗。它們都配合到麵食的基本使用,又方便拿著,只是材料上的分別,所以就集中在目前這兩個選擇。
重量和體積在我的使用上都不大問題,因為預長期放公司使用,只有幾步路的需要。物料上雖然比較安心骨瓷。最最重視的是材料在使用過程上的體驗,因為之前用玻璃飯盒的經驗,不想令人有容易打破的憂慮。900ml的Soup Mug 在想到一手拿著空杯外出時的樣子,就差不多放棄了。公司產品目錄中有款850ml 的Breakfast Bow應該是最合適的,不過未見香港有貨。940ml現貨的Noodle Bow雖然大了點,但也許適合公司的自選沙律的容量,還有其他餐廳的份量。
今個月返late shift,要暫別我的早餐了。下個月準備出發旅行了,基本每日湯麵之外,再發掘更多用途吧。

自己一直對有種附手柄和蓋的瓷碗有點興趣,而某日行過LOG-ON看到這款微波爐用的膠碗。它們都配合到麵食的基本使用,又方便拿著,只是材料上的分別,所以就集中在目前這兩個選擇。
 |
| 聚丙烯 Polypropylene (PP) |
 |
| 骨瓷 |
| 聚丙烯(PP) | 物料 | 骨瓷 |
|---|---|---|
| X - 膠質 | 成份 | O - 瓷土 |
| O - 輕身 | 重量 | X - 較重 |
| O - 不易打破 | 物流 | X - 需要小心 |
| O - 數十元 | 價錢 | O - 數十元 |
| O - 650-940 ml | 容量 | O - 670-784 ml |
| O - (相約) | 大小 | O - 4.75-5 吋 |
重量和體積在我的使用上都不大問題,因為預長期放公司使用,只有幾步路的需要。物料上雖然比較安心骨瓷。最最重視的是材料在使用過程上的體驗,因為之前用玻璃飯盒的經驗,不想令人有容易打破的憂慮。900ml的Soup Mug 在想到一手拿著空杯外出時的樣子,就差不多放棄了。公司產品目錄中有款850ml 的Breakfast Bow應該是最合適的,不過未見香港有貨。940ml現貨的Noodle Bow雖然大了點,但也許適合公司的自選沙律的容量,還有其他餐廳的份量。
今個月返late shift,要暫別我的早餐了。下個月準備出發旅行了,基本每日湯麵之外,再發掘更多用途吧。
2016年6月12日 星期日
[R] 複製-市盈率與後市關係之統計
最近好像少了Coding上的主題。上星期看到這篇文章:《以市盈率和股息率看後市統計》,正好想把這個作為R的練習。它統計在不同市盈率(P/E)之下,恆指在1個月以至1年之後是升還是跌。結論是:雖然恆指無論在高或低市盈率的短期(一個月)後,表現未見有特別;但當看一年或兩年後的話,則明顯升多跌少。而且市盈率越低,一年後及二年後上升的機會越大。
另一方面的市盈率資料,之前為了自己弄的Excel模型就有找過。可以用恆指公司網頁上的.xls檔案。因為在MacOS上沒有再找處理excel格式的套件,所以下載回來後,我先刪去了合併儲存格的大標題、改了日期格式、和另存成我熟悉的csv檔案。

這兩項數據有不同的日期表示方式,Yahoo用的是每月首個交易日,恆指公司用的卻是每月最後一日。所以先將兩項資料都用"zoo"格式的as.yearmon(index( )) 去轉換成配合這類月度資料的時間序列。將兩個數據合併,然後在所有數據中,再抽出所想要的時間片段。而與他的例子不同的是,我選擇了1987年1月至2016年5月的資料。
一開始只是計算某一個市盈率範圍在某個時間後的表現,這個可以比較簡單可以做到。然後就想要引伸到不同情況(5種市盈率範圍、5種觀察時期),還有要把每個結果整合到一個表格中來呈現,就只想到用nested-loop的方式去計算每一個數值,然後逐步組合成用於表達的Matrix。不過,其實這方法在R的世界中好像因為執行效率的考慮而儘量避免的,會比較推崇的是Vectorization,把數據一開始便弄成更多維度的矩陣去運算。
整個結果如下圖。

過程
想重複這個統計,需要的兩項資料分別是恆指收市價和恆指市盈率。在練習R時,收市價當然是用它的Library: "quantmod" 。背後的數據來源是Yahoo財經;因為今次需要的是月度資料(之後提到的恆指PE,要方便的話也是拿按月的資料),所以用compression="m";再用"zoo"格式的as.yearmon(index( )) 紀錄這類月度的時間序列。Prices = get.hist.quote(instrument="^hsi", start="1986-01-01",end="2016-05-31",
quote=c("Close","AdjClose"),provider="yahoo",
origin="1970-01-01",compression="m", retclass="zoo")
另一方面的市盈率資料,之前為了自己弄的Excel模型就有找過。可以用恆指公司網頁上的.xls檔案。因為在MacOS上沒有再找處理excel格式的套件,所以下載回來後,我先刪去了合併儲存格的大標題、改了日期格式、和另存成我熟悉的csv檔案。

這兩項數據有不同的日期表示方式,Yahoo用的是每月首個交易日,恆指公司用的卻是每月最後一日。所以先將兩項資料都用"zoo"格式的as.yearmon(index( )) 去轉換成配合這類月度資料的時間序列。將兩個數據合併,然後在所有數據中,再抽出所想要的時間片段。而與他的例子不同的是,我選擇了1987年1月至2016年5月的資料。
一開始只是計算某一個市盈率範圍在某個時間後的表現,這個可以比較簡單可以做到。然後就想要引伸到不同情況(5種市盈率範圍、5種觀察時期),還有要把每個結果整合到一個表格中來呈現,就只想到用nested-loop的方式去計算每一個數值,然後逐步組合成用於表達的Matrix。不過,其實這方法在R的世界中好像因為執行效率的考慮而儘量避免的,會比較推崇的是Vectorization,把數據一開始便弄成更多維度的矩陣去運算。
整個結果如下圖。

2016年6月4日 星期六
Office Life - 外賣膠飯盒的重用試驗
自備飯盒的測試不敵自己的玻璃盒對熱麵的不方便,放低了一段日子後,但外賣時老是帶點猶豫。最近隔離位的同事提到他也會買把早餐的塑膠碗重用幾次,覺得這也不失為一個方法。這樣就解決了飯盒的設計如何適合餐廳運作和我所點的食物這些問題。也想起另一個重用的例子是樓下飯堂中午的自選沙律。之前遇過有個外藉職員買沙律時都是自備的。當時未留意這些膠盒的自己,看他氣憤般怪店員又給了它一個膠盒,只有感到好奇。
同身邊同事們也傾到這可以重用多少次。有人認為五次,而我當時純感覺的話是放一星期就該丟棄。因為猶豫的都是會否什麼有害物質。尤其它要經得起一次次的熱湯(在公司的早餐我是傾向食粉麵的)和洗潔精。傾完之後,接著就當然要親自嘗試,帶著乾淨的膠碗到職員餐廳,在點了早餐後把碗交給煮麵阿姐,自己不會擔心打破或放置,就轉去另一邊點飲品,完全配合到本來的流程。最後一樣地拍卡俾錢,帶回工作枱邊做邊食早餐。有空才把膠碗拿去茶水間,簡單地用點洗潔精洗,不過清洗時會感到質地比重覆使用的飯盒軟身得多。我知道用力去清潔才最乾淨,但一用力清洗時,就有點擔心質量上有沒有問題⋯⋯另外,用這種配合指定食物的盒子,才發覺自己並不是經常都想食同一款食物的。粉麵可能一星期兩三次,隔星期食下沙律,另外有時食粥,有時三文治⋯⋯枱面就放了不同款式的膠盒,一星期內的重用度不是那麼高。


同身邊同事們也傾到這可以重用多少次。有人認為五次,而我當時純感覺的話是放一星期就該丟棄。因為猶豫的都是會否什麼有害物質。尤其它要經得起一次次的熱湯(在公司的早餐我是傾向食粉麵的)和洗潔精。傾完之後,接著就當然要親自嘗試,帶著乾淨的膠碗到職員餐廳,在點了早餐後把碗交給煮麵阿姐,自己不會擔心打破或放置,就轉去另一邊點飲品,完全配合到本來的流程。最後一樣地拍卡俾錢,帶回工作枱邊做邊食早餐。有空才把膠碗拿去茶水間,簡單地用點洗潔精洗,不過清洗時會感到質地比重覆使用的飯盒軟身得多。我知道用力去清潔才最乾淨,但一用力清洗時,就有點擔心質量上有沒有問題⋯⋯另外,用這種配合指定食物的盒子,才發覺自己並不是經常都想食同一款食物的。粉麵可能一星期兩三次,隔星期食下沙律,另外有時食粥,有時三文治⋯⋯枱面就放了不同款式的膠盒,一星期內的重用度不是那麼高。


2016年5月29日 星期日
Arduino 的 Starter-Kit Project
Arduino 的 Starter-Kit Project,跟著試做已經進行到第5個教學例子。自從跟身邊朋友講起之後,原來也有些朋友有玩過Arduino,有學過電子的同事,學電腦設計的舊同學,點子活動中的新相識,都對這個有點認識。只是大概網上資源香港還是不多,主要仍然是台灣人架的網站,書店和圖書館也有少數台灣書可以找到。而香港除了我入手的RS Components外,還有深水埗黃金對面的福仁商場G37-Tell How Technology有賣。有一個叫Dim Sum Lab 的空間可以讓香港的同好交流,有點像Maker Bay的形式,但是不同的主題。
Arduino 是一塊電路板和編程語言的整合。但它卻讓很多沒有任何電工或編程經驗的人也可以開始動手做電子硬體的控制。它也是作為一個開源項目,讓社群的人可以在它的基礎上改善和發展,出現後推動了一股稱為自做者/創客的文化。它在電路上整合了微控制器(例如Arduino Uno上的ATmega328P),輸入輸出介面(各種Pin位、USB接口);當結合各種電子元件(如開關、感測器、LED、步進馬達),和配合Arduino語言(類似C)的程式開發環境,便可以嘗試自做一些電子機器。而特別令我感興趣的,是它讓自己可以連繫起軟體和硬體。看到網上的高手可以自行開發出很酷的東西:
<駭客只要用這個USB充電器,就可以竊取你的無線鍵盤輸入資料>
http://www.techbang.com/posts/21946
<將Arduino 變成Game Boy,還可自行設計遊戲的Arduboy>
http://www.techbang.com/posts/23764
<什麼樣的工程師能上太空?13 歲少年玩 Arduino,玩到被送上太空!>
http://buzzorange.com/techorange/2013/10/14/thirteen-year-olds-hack-their-way-into-space/
<簡易Arduino機器人製作>
http://www.makezine.com.tw/make2599131456/arduino13
說它是開源項目因為當初開發團隊的決定是開放這個項目的設計,只有Arduino這個名稱、標誌以及圖案是受保護的商標(不過,現在有關於 arduino.cc和 arduino.org的分別)。硬件的電子連接都是在創意共享Creative Common Attribution Share-Alike 授權條款去公開原設計文件,可以讓人模仿、以至修改成自己所需的底板或相容系統,他們的網頁上就有教如何自製一塊Arduino。就不同的需要,它們自家開發的就有初學者入手的Arduino UNO、細小便攜的Arduino Mini、可穿戴和縫紉在衣服上的LilyPad Arduino、有WIFI和增強了運算能力Arduino Yun等,其他人仕自行開發的有Intel Galileo, Webduino, 等。Arduino的社群中,在底板以上還有著不同的擴充板(Shield)可以擴充它的功能,如Motor Shield、Ethernet Shield等。而程式方面,用家可以在提供的IDE介面自行編寫控制程式(Sketch),而且還有各種的函式庫可以引用或自建。
Arduino 是一塊電路板和編程語言的整合。但它卻讓很多沒有任何電工或編程經驗的人也可以開始動手做電子硬體的控制。它也是作為一個開源項目,讓社群的人可以在它的基礎上改善和發展,出現後推動了一股稱為自做者/創客的文化。它在電路上整合了微控制器(例如Arduino Uno上的ATmega328P),輸入輸出介面(各種Pin位、USB接口);當結合各種電子元件(如開關、感測器、LED、步進馬達),和配合Arduino語言(類似C)的程式開發環境,便可以嘗試自做一些電子機器。而特別令我感興趣的,是它讓自己可以連繫起軟體和硬體。看到網上的高手可以自行開發出很酷的東西:
<駭客只要用這個USB充電器,就可以竊取你的無線鍵盤輸入資料>
http://www.techbang.com/posts/21946
<將Arduino 變成Game Boy,還可自行設計遊戲的Arduboy>
http://www.techbang.com/posts/23764
<什麼樣的工程師能上太空?13 歲少年玩 Arduino,玩到被送上太空!>
http://buzzorange.com/techorange/2013/10/14/thirteen-year-olds-hack-their-way-into-space/
<簡易Arduino機器人製作>
http://www.makezine.com.tw/make2599131456/arduino13
說它是開源項目因為當初開發團隊的決定是開放這個項目的設計,只有Arduino這個名稱、標誌以及圖案是受保護的商標(不過,現在有關於 arduino.cc和 arduino.org的分別)。硬件的電子連接都是在創意共享Creative Common Attribution Share-Alike 授權條款去公開原設計文件,可以讓人模仿、以至修改成自己所需的底板或相容系統,他們的網頁上就有教如何自製一塊Arduino。就不同的需要,它們自家開發的就有初學者入手的Arduino UNO、細小便攜的Arduino Mini、可穿戴和縫紉在衣服上的LilyPad Arduino、有WIFI和增強了運算能力Arduino Yun等,其他人仕自行開發的有Intel Galileo, Webduino, 等。Arduino的社群中,在底板以上還有著不同的擴充板(Shield)可以擴充它的功能,如Motor Shield、Ethernet Shield等。而程式方面,用家可以在提供的IDE介面自行編寫控制程式(Sketch),而且還有各種的函式庫可以引用或自建。
2016年5月21日 星期六
Edx - TW3421x Credit Risk Management
Edx 上看到一個Credit Risk Management的課堂,報了打算讓自己溫習一下從前上課所學。最近這快要完成了,來總結這課堂所學的內容。
這課堂由Delft University of Technology的Dr. Pasquale Cirillo 講授。說話速度像是刻意放慢了,講解不會沉悶之餘,初時還有用RSA動畫的方式去解釋事情之間關係。內容方面,沒有涉及複雜的數學證明,某些公式出現時就重申:推導過程不在課程以內,然後直接使用。這令課程變得簡單之餘,也清晰了這是集中在讓初學者理解概念。
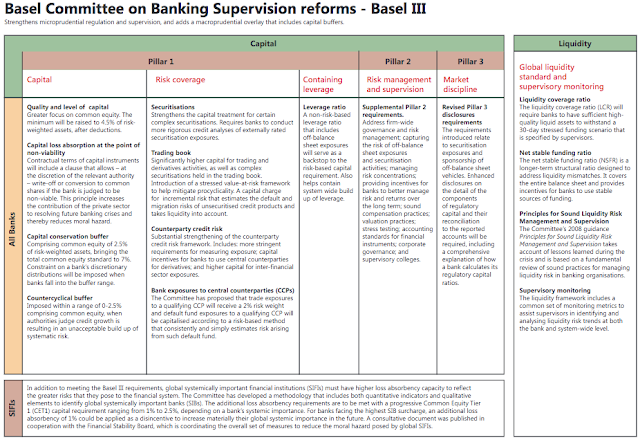
課程把信用風險放在從巴塞爾協定中開始講起。巴塞爾協定是對銀行業的其中一項重要條約。從巴塞爾協定二起,基本定立出三條支柱。
1) Minimum Capital Requirement (Credit Risk, Market Risk, Operational Risk)
2) Supervisory Review Process
3) Market Discipline
更仔細的在:http://www.bis.org/bcbs/basel3/b3summarytable.pdf
這課堂由Delft University of Technology的Dr. Pasquale Cirillo 講授。說話速度像是刻意放慢了,講解不會沉悶之餘,初時還有用RSA動畫的方式去解釋事情之間關係。內容方面,沒有涉及複雜的數學證明,某些公式出現時就重申:推導過程不在課程以內,然後直接使用。這令課程變得簡單之餘,也清晰了這是集中在讓初學者理解概念。
The computation of WCDR is performed using the formula you see on your screen. I do agree with you if you think that this formula has somehow fallen from the sky.
That's true: in this course this formula has fallen from the sky. The point is that, in order to derive this formula completely and formally, we would need - all - a big probabilistic apparatus that we do not have, such as for example the copula model. So, that's it: just take this formula for granted.
課程把信用風險放在從巴塞爾協定中開始講起。巴塞爾協定是對銀行業的其中一項重要條約。從巴塞爾協定二起,基本定立出三條支柱。
1) Minimum Capital Requirement (Credit Risk, Market Risk, Operational Risk)
2) Supervisory Review Process
3) Market Discipline
更仔細的在:http://www.bis.org/bcbs/basel3/b3summarytable.pdf

2016年5月8日 星期日
生活雙週 - 空手道, 魚仔板, Udemy, Arduino
這兩星期為之後的日子突然又下了幾個決定/行動。
同事推介一起上柔術的課,正正讓我面對一直在意的一個主意:重新空手道的練習。自從某天在地鐵上遇到大昭師兄後,大概都有了回去的決心。今晚剛剛回去了空手道的練習,身體和技術都未有怎樣生疏;征遠鎮和拔塞大的動作練幾次也記得了;但只有之前也記不上的那些套拳分解,仍是忘了大半。早兩年一直有為自己定下一些目標,但大概受著擔心和討厭今年就算定下了,也未會實踐這個目標,而一直未為今年打算。但現在開始了,這就好了。想做又應該做的事,不應該因為害怕令自己停步,「怯,你就輸成世」。
在Skatecity買了塊平價的Street牌魚仔板,晚上到吐露港沿單車徑旁的行人路試踩。記得是焜哥和店員所講的都是踩著前面釘位,不過第一晚試踩並不容易,人的重心和滑板的移動總是不配合。學習時未想在單車路上,行人路是紅磚式的地面,隙縫的阻力也很大,不斷只有幾步幾步距離地移動。到有個位置是旁邊有休憩處的,那地面就沒那麼粗糙,合適得多,試過這段路後,沿行人路回去時也順了點,後腳也放到板上。之後放在家時找些YouTube上的penny教學,記得幾段基本滑行、轉彎、Tictap。前晚就去了另一個公園的緩跑徑練習,慢慢繞過一圈後就感覺開始掌握到平衝感。然後繞了幾圈到凌晨才回家。今早到附近「觀星台」的空地練習,算每一次嘗試上板/滑前/轉彎(右)都可以了。
PMP 的 35 contact hours, 終於在Udemy 找到平價之選,LearnSmart LLC的Project Management Professional,只要 USD$20。標榜是PMI的Registered Education Provider (R.E.P.),完成課程後的證書可以作為報PMP考試要求的35 Contact hour 。 影片的講解尚算有條理及清晰,還可以在手機App下載起來,然後在上下班時去看,暫時完成了13%的進度。因為自己上年在考慮的時候己經把圖書館借來的書看完一次,不是只靠它的影片開始從零學習,所以只算是在用來覆習和要知道PMBOK5更新的部分。如果要備試的話我覺得更重要的還是做練習,現在尚未看它的習題,下載起首幾課的補充資源中就都有包括crossword puzzle/ flash card / quiz 等等,大概都是之後自學都會用的。
在看工聯會除了同事介紹的柔術外還有什麼課程時,自己又想找一些電子工程的知識學習。看到有教授Arduino的課堂,想起早幾天在圖書舘看過這名字的,於是再找想關的介紹或學習。找到其他電工會的課程也差不多價錢,而且連零件實習的還另需零件的費用,當想找找那裡可以買到時,原來官方也有出一套Starter Kit, 有一塊Arduino UNO, 可以跟著學習的Projects Book和相關電子零件等。在RS 這個電子零件商入手買了。不知是否香港不算著普及,少有個人提及Arduino,下單後也因為RS香港未有貨,而要等海外運送。在一個星期後終於送到屋企,相比電話聯絡時他們預估的快了兩天。
最後,還有7月義大利之行的機票,比之前搜尋時貴了,不過決定還是會去的。這個工作營從知道的一刻,一直在一個兩難的選擇的猶豫中,因為日子可能跟工作上的一個專案相撞。不過經番思量,這個工作上的機遇,就當凡事留一線吧。義大利:作為一直想看看的歐洲城市,一次非工幹的旅行,期望多些新鮮體驗吧。
同事推介一起上柔術的課,正正讓我面對一直在意的一個主意:重新空手道的練習。自從某天在地鐵上遇到大昭師兄後,大概都有了回去的決心。今晚剛剛回去了空手道的練習,身體和技術都未有怎樣生疏;征遠鎮和拔塞大的動作練幾次也記得了;但只有之前也記不上的那些套拳分解,仍是忘了大半。早兩年一直有為自己定下一些目標,但大概受著擔心和討厭今年就算定下了,也未會實踐這個目標,而一直未為今年打算。但現在開始了,這就好了。想做又應該做的事,不應該因為害怕令自己停步,「怯,你就輸成世」。
在Skatecity買了塊平價的Street牌魚仔板,晚上到吐露港沿單車徑旁的行人路試踩。記得是焜哥和店員所講的都是踩著前面釘位,不過第一晚試踩並不容易,人的重心和滑板的移動總是不配合。學習時未想在單車路上,行人路是紅磚式的地面,隙縫的阻力也很大,不斷只有幾步幾步距離地移動。到有個位置是旁邊有休憩處的,那地面就沒那麼粗糙,合適得多,試過這段路後,沿行人路回去時也順了點,後腳也放到板上。之後放在家時找些YouTube上的penny教學,記得幾段基本滑行、轉彎、Tictap。前晚就去了另一個公園的緩跑徑練習,慢慢繞過一圈後就感覺開始掌握到平衝感。然後繞了幾圈到凌晨才回家。今早到附近「觀星台」的空地練習,算每一次嘗試上板/滑前/轉彎(右)都可以了。
PMP 的 35 contact hours, 終於在Udemy 找到平價之選,LearnSmart LLC的Project Management Professional,只要 USD$20。標榜是PMI的Registered Education Provider (R.E.P.),完成課程後的證書可以作為報PMP考試要求的35 Contact hour 。 影片的講解尚算有條理及清晰,還可以在手機App下載起來,然後在上下班時去看,暫時完成了13%的進度。因為自己上年在考慮的時候己經把圖書館借來的書看完一次,不是只靠它的影片開始從零學習,所以只算是在用來覆習和要知道PMBOK5更新的部分。如果要備試的話我覺得更重要的還是做練習,現在尚未看它的習題,下載起首幾課的補充資源中就都有包括crossword puzzle/ flash card / quiz 等等,大概都是之後自學都會用的。
在看工聯會除了同事介紹的柔術外還有什麼課程時,自己又想找一些電子工程的知識學習。看到有教授Arduino的課堂,想起早幾天在圖書舘看過這名字的,於是再找想關的介紹或學習。找到其他電工會的課程也差不多價錢,而且連零件實習的還另需零件的費用,當想找找那裡可以買到時,原來官方也有出一套Starter Kit, 有一塊Arduino UNO, 可以跟著學習的Projects Book和相關電子零件等。在RS 這個電子零件商入手買了。不知是否香港不算著普及,少有個人提及Arduino,下單後也因為RS香港未有貨,而要等海外運送。在一個星期後終於送到屋企,相比電話聯絡時他們預估的快了兩天。
最後,還有7月義大利之行的機票,比之前搜尋時貴了,不過決定還是會去的。這個工作營從知道的一刻,一直在一個兩難的選擇的猶豫中,因為日子可能跟工作上的一個專案相撞。不過經番思量,這個工作上的機遇,就當凡事留一線吧。義大利:作為一直想看看的歐洲城市,一次非工幹的旅行,期望多些新鮮體驗吧。
2016年5月1日 星期日
賭波的初哥方式-Elo Rating System 的理解
之前在未了解背後數學之前先嘗試個應用。今個周未有空就來了解一下Elo Rating System背後是什麼理論,和如何得出那樣的公式了。
Part A)機率
先來看看「邏輯函数」Logistic Function。在很多地方都會看到它的身影,例如物種的人口增長,統計學上的對True/False這類二元結果的回歸分析。
 「邏輯函数」 有這樣的一般型式:$$y = \frac{L}{ 1 + e^{-k(x-x_0)} }$$
「邏輯函数」 有這樣的一般型式:$$y = \frac{L}{ 1 + e^{-k(x-x_0)} }$$
$e$ :自然對數
$x_0$:x 的中間值
$L$ :y 的最大值
$k$ :斜度
例子一:Standard Logistic Function:$y = \frac{1}{1 + e^{-x}}$
例子二:國際象棋界 USCF 的 Elo rating system 的勝率期望值:$y = \frac{1}{1 + 10^{-\frac{1}{400}(r_A-r_B)}}$
我們考慮代入的是「分數差」(甲的分數-乙的分數), 即是$x=(r_A-r_B)$,$x_0=0$。一個函數可以作為「分數」 與「勝負機率」的轉換,大概很多$\mathbb{R} \to (0,1)$ 的函數都可以做到。而這「邏輯函数」還有以下特質::
「邏輯函数」 在統計模型的重要性在於與「邏輯迴歸」Logistic Regression 的關係。
Logistic Regression Model與一般的「簡單線性迴歸」 Ordinary Linear Regression都是屬於GLM的其中一員,分別在於對「應變數」Dependent Variable的分佈,和所謂的「連結函數」Link Function有不同假設。Logistic Regression Model中,Y 的分佈是要配合"勝/負"這類二元結果, 連結函數的不同就得出機會率可以寫成Logistic Function的形式。Logistic Regression :
$$logit( E [Y | X] ) = ln(\frac{p}{1-p}) = \beta X$$
對觀察值Y的分佈假設為 $Y \sim Binomial (1 , p) $。上式經過移項後會得到:$p = \frac{1}{1 + e^{-\beta X}}$,也就是開始時所見的Logistic Function的形式。

終於,我們回來看看Elo Ratings中的機率公式:
$$S_{expect} = \frac{1}{1 + 10^{-\frac{1}{400}(r_A-r_B)}}$$
Part B)分數
每名棋手會有一個初始分數$r_0$,然隨著實際對賽的結果,用以下公式更新棋手成積:
$$r_{post} = r_{pre} + K (S_{actual} - S_{expect})$$
$r_{post}$:對賽後棋手經調整後的分數。
$r_{pre}$:對賽前棋手原來的分數。
$S_{actual}$:實際結果,簡單可以設定:贏=1分,輸=0分,和=0.5分。
$S_{expect}$:預期結果,就是PartA計算甲會贏的機率公式。
$K$:這一般稱作attenuation factor,是調整新結果的影響和原有分數之間的比重。
一般會有這些考慮:假設比賽結果對新手影響較大,假設重要比賽的影響較大。
因為兩個等級的選手對賽,可以預期分數高的有較大贏面。棋手的分數要值得調整,他應該要表現得超越自己原有等級所預期的水準。Elo Rating更新分數的公式的設計就是為了達到這個效果。
另外,例如有 1200分的棋手A 和 1000分的棋手B 比賽:A,B的預期贏面分別算出是76%, 24%。 A勝出只會增加$0.24K$的分數,B勝出卻會增加$0.74K$的分數。所以:贏(輸)了該贏(輸)的比賽,分數不會有大幅調整;但如果出現戲劇性的結果,分數的調整就會較大。
Part C)應用
這套Elo Rating System在以下幾方面都有被應用:
遊戲:
League Of Legends
http://leagueoflegends.wikia.com/wiki/Elo_rating_system
國際象棋界:
World Chess Federation (FIDE)
https://www.fide.com/fide/handbook.html?id=172&view=article
足球:
World Football Elo Ratings
http://www.eloratings.net/system.html
FIFA Women's World Rankings
http://www.fifa.com/worldranking/procedureandschedule/womenprocedure/index.html
http://resources.fifa.com/mm/document/fifafacts/r%26a-wwr/52/00/99/fs-590_06e_wwr-new.pdf
Footballdatabase.com (雖然無提供背後的模型,但如果沒有數據作自行測試的話也可以一看)
http://footballdatabase.com/ranking/europe/1
因為各方面的比賽有不同特質,所以模型參數略有不同。用以上的 FIFA Women’s World Ranking (WWR) 的模型去看足球方面的實際運作(這裡修改了官方符號方便表示):
$$S_{expect} = 1 / (1 + 10^{x/2})$$
$$ r_{new} = r_{old} + K ( S_{actual} - S_{expect} )$$
文件中稱當中 $x = [r_A - r_B] / (\text{scaling factor})$。scaling factor是為了令新隊伍從1000分開始;對賽中每100分的差距做成64%的的機會勝出。用Excel模擬一下會得到它的scaling factor = -200,所以一樣是這條式:$S_{expect} = 1 / (1 + 10^{-\frac{1}{400}(r_A-r_B)})$



------------
最後一部份,我是懷疑是否有關的,是這套評分和Exponential Distribution的關係。
因為:$A, B \sim Exp(1) \Rightarrow x_0 - \beta ln(A/B) \sim Logistic(x_0, \beta)$
設$R_A, R_B \sim Exp(\dot)$ A,B 是某種實力的量度。Exponential distribution 的圖明顯與Normal Distribution 不同的,它假設選手的$R_A, R_B$ 大多是在低實力區,高手則愈來愈少。它還有一個特點,是分佈上的「無記憶性質」(Memoryless):$Pr(X>m+n|X>m) = Pr(X>n)$ 。對給定的任意一個參考分數而言,比你高同樣n級的比例是一樣的。用一個效果比喻:無論是在哪一級的角色,在下一個等級之前,總是有面前的人當中最弱的3%等著你去超越。
( 以$Exp(1/30)$為例。平均等級是30級。R:pexp(1, rate=1/30) )
設$R_a=ln(R_A), R_b=ln(R_B)$ 。用$ln()$將實力的比例尺轉變成方便比較的分數,$log()$這個運算的起源,是當年在未有計算機的發明之前,有一樣叫對數表的工具,為了方便計算大數的乘法。
$a-b = ln(exp(Ra-Rb)) = ln(exp(Ra)/exp(Rb)) = ln(A/B) \sim Logistic(0,1)$
這就得出分數差會符合Logistic Distribution.
但這是否有什麼意義呢?未想清楚。。。
------------
Part A)機率
先來看看「邏輯函数」Logistic Function。在很多地方都會看到它的身影,例如物種的人口增長,統計學上的對True/False這類二元結果的回歸分析。

$e$ :自然對數
$x_0$:x 的中間值
$L$ :y 的最大值
$k$ :斜度
例子一:Standard Logistic Function:$y = \frac{1}{1 + e^{-x}}$
例子二:國際象棋界 USCF 的 Elo rating system 的勝率期望值:$y = \frac{1}{1 + 10^{-\frac{1}{400}(r_A-r_B)}}$
我們考慮代入的是「分數差」(甲的分數-乙的分數), 即是$x=(r_A-r_B)$,$x_0=0$。一個函數可以作為「分數」 與「勝負機率」的轉換,大概很多$\mathbb{R} \to (0,1)$ 的函數都可以做到。而這「邏輯函数」還有以下特質::
- 這函數可以輸入實數的「分數差」,而輸出0到1之間的機率值;而且數值是不斷上升的,所以差異愈大,贏(輸)機率就愈大。(這兩個特質就適合用來作"分數差" 和"輸贏機率"之間的轉換)
- 零作為中間點是反向對稱的 $Pr(x)=1-Pr(-x)$,高分方的勝率等於低分方的負率。當雙方實力相等,也就是"分數差"在等於零的時候,輸贏的機率是0.5。
- 而差異愈接近零的時候機率的變化的速度較大;但差異愈大的時候,這個機率的變化速度就愈不明顯。(這個有點像經濟學上「邊際效益遞減」的概念,現實上有點猶豫)
「邏輯函数」 在統計模型的重要性在於與「邏輯迴歸」Logistic Regression 的關係。
Logistic Regression Model與一般的「簡單線性迴歸」 Ordinary Linear Regression都是屬於GLM的其中一員,分別在於對「應變數」Dependent Variable的分佈,和所謂的「連結函數」Link Function有不同假設。Logistic Regression Model中,Y 的分佈是要配合"勝/負"這類二元結果, 連結函數的不同就得出機會率可以寫成Logistic Function的形式。Logistic Regression :
$$logit( E [Y | X] ) = ln(\frac{p}{1-p}) = \beta X$$
對觀察值Y的分佈假設為 $Y \sim Binomial (1 , p) $。上式經過移項後會得到:$p = \frac{1}{1 + e^{-\beta X}}$,也就是開始時所見的Logistic Function的形式。

終於,我們回來看看Elo Ratings中的機率公式:
$$S_{expect} = \frac{1}{1 + 10^{-\frac{1}{400}(r_A-r_B)}}$$
- 從 $e$ 變成 10的次方:因為 $10^x = {e^{ln(10)}}^x =e^{ln(10)x} $,這只是在$k$值的影響。
- $k$:1/400,這個斜度是雙方選手的分數差如何轉換到 0-1的比例上。例如當同樣估計為A勝B,但估計的機率是60%還是70%就是這k值影響到。在線性回歸中我們會用OLS的方法去求取參數,在 Logistic Regression中參數是用「最大似然估計」Maximum Likelihood Estimation (MLE)找出來。
- $r_A, r_B$:選手的分數,這裡並不是一個可以直接觀察到的自變數,如何得出這分數就是Elo Rating 的另一重要部份。
Part B)分數
每名棋手會有一個初始分數$r_0$,然隨著實際對賽的結果,用以下公式更新棋手成積:
$$r_{post} = r_{pre} + K (S_{actual} - S_{expect})$$
$r_{post}$:對賽後棋手經調整後的分數。
$r_{pre}$:對賽前棋手原來的分數。
$S_{actual}$:實際結果,簡單可以設定:贏=1分,輸=0分,和=0.5分。
$S_{expect}$:預期結果,就是PartA計算甲會贏的機率公式。
$K$:這一般稱作attenuation factor,是調整新結果的影響和原有分數之間的比重。
一般會有這些考慮:假設比賽結果對新手影響較大,假設重要比賽的影響較大。
因為兩個等級的選手對賽,可以預期分數高的有較大贏面。棋手的分數要值得調整,他應該要表現得超越自己原有等級所預期的水準。Elo Rating更新分數的公式的設計就是為了達到這個效果。
另外,例如有 1200分的棋手A 和 1000分的棋手B 比賽:A,B的預期贏面分別算出是76%, 24%。 A勝出只會增加$0.24K$的分數,B勝出卻會增加$0.74K$的分數。所以:贏(輸)了該贏(輸)的比賽,分數不會有大幅調整;但如果出現戲劇性的結果,分數的調整就會較大。
Part C)應用
這套Elo Rating System在以下幾方面都有被應用:
遊戲:
League Of Legends
http://leagueoflegends.wikia.com/wiki/Elo_rating_system
國際象棋界:
World Chess Federation (FIDE)
https://www.fide.com/fide/handbook.html?id=172&view=article
足球:
World Football Elo Ratings
http://www.eloratings.net/system.html
FIFA Women's World Rankings
http://www.fifa.com/worldranking/procedureandschedule/womenprocedure/index.html
http://resources.fifa.com/mm/document/fifafacts/r%26a-wwr/52/00/99/fs-590_06e_wwr-new.pdf
Footballdatabase.com (雖然無提供背後的模型,但如果沒有數據作自行測試的話也可以一看)
http://footballdatabase.com/ranking/europe/1
因為各方面的比賽有不同特質,所以模型參數略有不同。用以上的 FIFA Women’s World Ranking (WWR) 的模型去看足球方面的實際運作(這裡修改了官方符號方便表示):
$$S_{expect} = 1 / (1 + 10^{x/2})$$
$$ r_{new} = r_{old} + K ( S_{actual} - S_{expect} )$$
文件中稱當中 $x = [r_A - r_B] / (\text{scaling factor})$。scaling factor是為了令新隊伍從1000分開始;對賽中每100分的差距做成64%的的機會勝出。用Excel模擬一下會得到它的scaling factor = -200,所以一樣是這條式:$S_{expect} = 1 / (1 + 10^{-\frac{1}{400}(r_A-r_B)})$

- 它們對模型的修改上考慮到入球數目的不同:

- 主場的優勢:主隊加100分
"A glance at the historical results shows that teams perform better at home than away; the home teams keep 66% of the points, while the opponents return home with 34%. To neutralise this effect, a correction is made by enhancing the rating of the home team by a value of 100 points (corresponding to 64%)."
- 對於賽事重要性:

- 參考的時間歷史:45年的比賽紀錄,在評分的角度上還可以接受,但我覺得對勝負機會率的目的來說就太多。現在的球隊隊員跟好幾年前的早就不同了吧。
"Solid foundation: some 6500 games since 1971"
- 開始評分所需的數據:其實我覺得這套方式比較適合LOL遊戲平台上的計分,那時每次分數更新反映的是一個學習過程。但在象棋/足球這類大量練習,然後參加一場聯賽的情況中,每次分數更新就像是尋求反映真正實力的過程,這就要有足夠對實往績能達到效果。事實上,也因為Logistic Regression 的參數是用到MLE的方法,一般需要的樣本數也要較大。
"The ranking of a team is deemed official when:They have played at least 5 matches against teams with an official ranking. etc..."
------------
最後一部份,我是懷疑是否有關的,是這套評分和Exponential Distribution的關係。
因為:$A, B \sim Exp(1) \Rightarrow x_0 - \beta ln(A/B) \sim Logistic(x_0, \beta)$
設$R_A, R_B \sim Exp(\dot)$ A,B 是某種實力的量度。Exponential distribution 的圖明顯與Normal Distribution 不同的,它假設選手的$R_A, R_B$ 大多是在低實力區,高手則愈來愈少。它還有一個特點,是分佈上的「無記憶性質」(Memoryless):$Pr(X>m+n|X>m) = Pr(X>n)$ 。對給定的任意一個參考分數而言,比你高同樣n級的比例是一樣的。用一個效果比喻:無論是在哪一級的角色,在下一個等級之前,總是有面前的人當中最弱的3%等著你去超越。
( 以$Exp(1/30)$為例。平均等級是30級。R:pexp(1, rate=1/30) )
設$R_a=ln(R_A), R_b=ln(R_B)$ 。用$ln()$將實力的比例尺轉變成方便比較的分數,$log()$這個運算的起源,是當年在未有計算機的發明之前,有一樣叫對數表的工具,為了方便計算大數的乘法。
$a-b = ln(exp(Ra-Rb)) = ln(exp(Ra)/exp(Rb)) = ln(A/B) \sim Logistic(0,1)$
這就得出分數差會符合Logistic Distribution.
但這是否有什麼意義呢?未想清楚。。。
------------
2016年4月25日 星期一
賭波的初哥方式一檢討
八強賽事完結,結果是不好的了。但這初哥當初決定放入少許注碼,希望投入到去體驗,實際地知道到了什麼:
1. 注碼佔口袋裡錢的比例要更少。當一注是本金的 1x - 20%,輸幾注就感覺很危險。
(這是不符合Kelly Criteria嗎?原來是自己用錯賠率了)
2. Kelly Criteria 用的是淨賠率,是馬會顯示的賠率-1。
(其實修正過後大部份場都不值得下注。這可能是低估了機會率,或馬會的給的賠率太低了。)
3. 足球不能簡化為勝負二個賽果。在一般的:主、客、和。當兩隊實力相約,和的機率其實不少,不能不考慮打和。而且相比單純贏輸幾球,最好可以有估波膽形式般的預測,這樣才能享用較高賠率。
4. 可以分開:得、失球 的能力,有人用過去的Poisson Distribution作工具,這應該可以考慮加入得失球分開的辦法。 或 之前的Least square estimation也應該這樣。而且這類方法目標是要有機率,要知誤差。
5. 要了解ELO背後模型,如何才能用在主客和3種情況。ELO的初始參數要做校準,去調整合適的機會率和界線。
---------------------------
這些有的是八強首圈時發現的,但還未花時間研究如何修改。下一場快上演了,更重要的是不能拖著自己寫Blog的進度。
1. 注碼佔口袋裡錢的比例要更少。當一注是本金的 1x - 20%,輸幾注就感覺很危險。
(這是不符合Kelly Criteria嗎?原來是自己用錯賠率了)
2. Kelly Criteria 用的是淨賠率,是馬會顯示的賠率-1。
(其實修正過後大部份場都不值得下注。這可能是低估了機會率,或馬會的給的賠率太低了。)
3. 足球不能簡化為勝負二個賽果。在一般的:主、客、和。當兩隊實力相約,和的機率其實不少,不能不考慮打和。而且相比單純贏輸幾球,最好可以有估波膽形式般的預測,這樣才能享用較高賠率。
4. 可以分開:得、失球 的能力,有人用過去的Poisson Distribution作工具,這應該可以考慮加入得失球分開的辦法。 或 之前的Least square estimation也應該這樣。而且這類方法目標是要有機率,要知誤差。
5. 要了解ELO背後模型,如何才能用在主客和3種情況。ELO的初始參數要做校準,去調整合適的機會率和界線。
---------------------------
這些有的是八強首圈時發現的,但還未花時間研究如何修改。下一場快上演了,更重要的是不能拖著自己寫Blog的進度。
2016年3月31日 星期四
賭波的初哥方式-Least Square Estimation & Elo Rating System
星期三放假在家,空閒的時間再嘗試一下去年的足球博彩模型。當時因為自己讀過點數學和統計,一直想有點實際的應用;朋友V想用模型預測球賽結果和博彩,而我工作時又會弄點程式來方便日常工作,所以去年就和我嘗試提高預測球賽結果的賺錢機會,以及做點自動化的工具。
去年,加入的是一個為每隊評分的方法。假設每隊有一個代表綜合實力的分數-Rating,而得失球的差-Score只是兩隊分數的差。用過往每隊的對賽結果,放入一個方程組(System of Linear Equations) $\underline{HA \times teamRank=Score}$ 去求最小方差(Least square estimation)的解,就可以反求出這些分數。
$$
\begin{bmatrix}
1 & 0 & 0 & -1 \\
0 & 1 & -1 & 0 \\
-1 & 0 & 1 & 0 \\
0 & -1 & 0 & 1 \\
0 & 0 & -1 & 1 \\
-1 & 1 & 0 & 0 \\
0 & 0 & 1 & -1 \\
1 & -1 & 0 & 0 \\
1 & 0 & 0 & -1 \\
-1 & 0 & 0 & 1 \\
0 & -1 & 1 & 0 \\
0 & 1 & 0 & -1 \\
0 & 1 & 0 & -1 \end{bmatrix}
\times
\begin{bmatrix}
1.375 \\
2 \\
-2.5 \\
-0.875 \end{bmatrix}
=
\begin{bmatrix}
2 \\
8 \\
-5 \\
-1 \\
4 \\
1 \\
1 \\
0 \\
-3 \\
-2 \\
2 \\
4 \end{bmatrix}$$
當然,我們想做的是把這些運算交給電腦。當只要做好數據的準備,在R上除了數據的輸入和顯示外,重要的運算就只是一行Coding:
去年,加入的是一個為每隊評分的方法。假設每隊有一個代表綜合實力的分數-Rating,而得失球的差-Score只是兩隊分數的差。用過往每隊的對賽結果,放入一個方程組(System of Linear Equations) $\underline{HA \times teamRank=Score}$ 去求最小方差(Least square estimation)的解,就可以反求出這些分數。
$$
\begin{bmatrix}
1 & 0 & 0 & -1 \\
0 & 1 & -1 & 0 \\
-1 & 0 & 1 & 0 \\
0 & -1 & 0 & 1 \\
0 & 0 & -1 & 1 \\
-1 & 1 & 0 & 0 \\
0 & 0 & 1 & -1 \\
1 & -1 & 0 & 0 \\
1 & 0 & 0 & -1 \\
-1 & 0 & 0 & 1 \\
0 & -1 & 1 & 0 \\
0 & 1 & 0 & -1 \\
0 & 1 & 0 & -1 \end{bmatrix}
\times
\begin{bmatrix}
1.375 \\
2 \\
-2.5 \\
-0.875 \end{bmatrix}
=
\begin{bmatrix}
2 \\
8 \\
-5 \\
-1 \\
4 \\
1 \\
1 \\
0 \\
-3 \\
-2 \\
2 \\
4 \end{bmatrix}$$
當然,我們想做的是把這些運算交給電腦。當只要做好數據的準備,在R上除了數據的輸入和顯示外,重要的運算就只是一行Coding:
以2013-2014年度英超對賽的紀錄作計算,最好幾隊分別是:teamRank = ginv(HA) %*% score;
- 曼城=1.625
- 利物浦=1.275
- 車路士=1.1
- 阿仙奴=0.675
- 愛華頓=0.55
2016年3月30日 星期三
GGC - Startup Challenge 後記:二
Day04-Google Weekend 2
因為前一晚在簡報方面有大變動,所以都預先也再和隊員夾定相關的準備。前一晚亦各自將ppt的內容寄給我們的Designer加工。今天的Pitching會在下午進行,會從14隊中挑選6隊進入決賽,而中午就要做採排和定好簡報,所以工作時間只有上午約2個小時。策略當然是先定好簡報,再不斷練習和改進講稿。簡報方面比昨晚構想中的5-6頁多,Slide的次序雖然有調動,但流程大抵不變。簡約的圖像是很好的表達方式,原來《獲利世代》那種思考商業模式的圖,用來作為計劃過程中的工具還好,但要放進一頁簡報中,就顯得太多文字了。我們練習時也從Mentor身上,學到很好的結尾方式:將我們最後整造的美好願景再有層次地擴大;最後一句話要用清晰有力的語調完結,更能讓意念在完結後留在聽眾腦海。
今次活動Day1開始前,主辦單位分享過兩段YouTube演講,一段有關設計的Designers -- Think Big!,一段是How frustration can make us more creative。今次的經驗體驗到第二段片的講法,我們臨時湊合的組員,除了能力背景的Diversity外,當然有著不同性格。有時會有爭論和說話態度上的不同。但的確當可以解決到不同人的想法時,會有更大效益。
一個問題之前一直未清晰的確是:我們到底是在做一場Campaign?還是一個賣產品的公司?而到今天,大概摸索到一種類似的NGO在主公司下設營利部門的模式(Foundation - Business Division)我們想影響的對象是大眾,但買單的顧客是企業。我們的核心價值是想推動一種風氣,在這主公司的角度下並不應該很介意日後沒有新客源或有競爭者。而營利部門是一方面向買家提供其他服務,另一方面吸引一批連帶的用家加入我們想推動建立的風氣。這種將推廣和營利分開的模式,從Green Monday的結構可以也可以看到。當要現實地考慮如何持續營運,同時參考了其他NGO的年報,就很好奇為什麼如綠色和平等一些NGO可以只靠捐款營運。
我的確覺得我們的Pitching做得很好,有很合適的講者和簡報,做到簡約、故事式、以想推動的價值觀打動聽眾。在公佈入圍的六隊時,數到我們時我自己未有很大的激動,為什麼一直會有這感覺,覺得應該會入圍呢?
Day05-Final Pitching
在Final Pitching 是在一星期後的星期六,最忙碌的日子就是這周,好幾天都是收工後繼續開會做準備,星期一和鄰隊來協助的去了MakerBay 準備飯盒的設計和期望可以製作一個初型。那邊可以用到的工具而技術上最可行的大概是3D Printing,MakerBay其中一個平日的有趣活動就是3D Printing 製作一部3D Printer。昨天新聞就提到NASA剛帶了一部可以在無重力下使用的3D Printer 上太空站,期望可以在太空自行製造零件而減輕運載升空的成本。不過當日也了解到一般3D Printer成品的質素仍未算理想,要加工磨走粗糙的地方,和打印時凌空部分的接駁(無重力的Printer應該解決到這問題?)。當日想到的飯盒設計如果有螺旋的接駁位,而非榫位的話,就應該未必適合3D printing。如果要推動人們的這個行為,整個設計也要考慮實用和外觀。設計一個特色的飯盒或許還容易,但要配合到餐廳的工作和用家的實用美觀,一個設計很難符合每種需要⋯⋯另外兩晚都到觀塘的工作室開會,就我們最弱的營利模式去設計活動,最後提供的服務算是面向HR的⻆度。另一方面,也簡單的寫下未來三年內按季的「現金」流向和相關活動,看著這張表,我認為經過這個準備,才會比較清楚之後要落實計劃時,有什麼先後程序上的鋪排。另外,我們想改變的是平日生活的習慣,所以都希望這星期大家親身嘗試體驗。


最後一日的決賽-以目標創業這件事就不是最後一天。大會向瑞信借場,在ICC上的寫字樓舉行。因應場地的熒幕尺寸,我們還是急急地再調整powerpoint。今次的評分方式不太一樣,是每位評審手上有不同比例的籌碼,總數十萬元,評審們以手上籌碼作評分之餘,也直接反映為每組最後的獎金。好處是可以直接反映他對該組的支持/模擬資金投資的角度;但另一方面人性上有分散投資這傾向的話,結果會趨向較為平均。相比「贏者全拿」的結果,應該誰也不會有足夠資金推動計劃,需要隊伍自身有很強的意念和力量去推動項目,以把這次獎金只視為部份資助,;但另一方面少了擔心單隊隊伍全拿後一筆過失敗的風險。這種模式在協助 "Greenovation" 和投資 "Startup" 的角度去考慮,如果我要保守地作出決策,大概現在這套也是好方法⋯⋯我們得到第二高的獎金,1st runner up。還有的是SaSa贊助的Voltra名額、香港航空機票、工匠灣會藉。
 無論如何,設計和演說的部份告一段落,下一步是最難的落實和運作。我所知道從投資角度看的創業是絕大部份失敗收場的。之後,好的眼光和高效率的運作缺一不可。要從想法進入到實際的階段,我看現在是需要一個領袖角色推動大家「做」這件事,需要一個擅長活動統籌和公關的角色實地「做」事。記得第一日workshop仁人學社的Mentor分享說:「記往:Ideas Are Cheap」。只有Idea做不了什麼,實際做得出來才重要。剛看完了《精實創業》,這刻感受最深的幾章都是:
無論如何,設計和演說的部份告一段落,下一步是最難的落實和運作。我所知道從投資角度看的創業是絕大部份失敗收場的。之後,好的眼光和高效率的運作缺一不可。要從想法進入到實際的階段,我看現在是需要一個領袖角色推動大家「做」這件事,需要一個擅長活動統籌和公關的角色實地「做」事。記得第一日workshop仁人學社的Mentor分享說:「記往:Ideas Are Cheap」。只有Idea做不了什麼,實際做得出來才重要。剛看完了《精實創業》,這刻感受最深的幾章都是:
因為前一晚在簡報方面有大變動,所以都預先也再和隊員夾定相關的準備。前一晚亦各自將ppt的內容寄給我們的Designer加工。今天的Pitching會在下午進行,會從14隊中挑選6隊進入決賽,而中午就要做採排和定好簡報,所以工作時間只有上午約2個小時。策略當然是先定好簡報,再不斷練習和改進講稿。簡報方面比昨晚構想中的5-6頁多,Slide的次序雖然有調動,但流程大抵不變。簡約的圖像是很好的表達方式,原來《獲利世代》那種思考商業模式的圖,用來作為計劃過程中的工具還好,但要放進一頁簡報中,就顯得太多文字了。我們練習時也從Mentor身上,學到很好的結尾方式:將我們最後整造的美好願景再有層次地擴大;最後一句話要用清晰有力的語調完結,更能讓意念在完結後留在聽眾腦海。
今次活動Day1開始前,主辦單位分享過兩段YouTube演講,一段有關設計的Designers -- Think Big!,一段是How frustration can make us more creative。今次的經驗體驗到第二段片的講法,我們臨時湊合的組員,除了能力背景的Diversity外,當然有著不同性格。有時會有爭論和說話態度上的不同。但的確當可以解決到不同人的想法時,會有更大效益。
一個問題之前一直未清晰的確是:我們到底是在做一場Campaign?還是一個賣產品的公司?而到今天,大概摸索到一種類似的NGO在主公司下設營利部門的模式(Foundation - Business Division)我們想影響的對象是大眾,但買單的顧客是企業。我們的核心價值是想推動一種風氣,在這主公司的角度下並不應該很介意日後沒有新客源或有競爭者。而營利部門是一方面向買家提供其他服務,另一方面吸引一批連帶的用家加入我們想推動建立的風氣。這種將推廣和營利分開的模式,從Green Monday的結構可以也可以看到。當要現實地考慮如何持續營運,同時參考了其他NGO的年報,就很好奇為什麼如綠色和平等一些NGO可以只靠捐款營運。
我的確覺得我們的Pitching做得很好,有很合適的講者和簡報,做到簡約、故事式、以想推動的價值觀打動聽眾。在公佈入圍的六隊時,數到我們時我自己未有很大的激動,為什麼一直會有這感覺,覺得應該會入圍呢?
Day05-Final Pitching
在Final Pitching 是在一星期後的星期六,最忙碌的日子就是這周,好幾天都是收工後繼續開會做準備,星期一和鄰隊來協助的去了MakerBay 準備飯盒的設計和期望可以製作一個初型。那邊可以用到的工具而技術上最可行的大概是3D Printing,MakerBay其中一個平日的有趣活動就是3D Printing 製作一部3D Printer。昨天新聞就提到NASA剛帶了一部可以在無重力下使用的3D Printer 上太空站,期望可以在太空自行製造零件而減輕運載升空的成本。不過當日也了解到一般3D Printer成品的質素仍未算理想,要加工磨走粗糙的地方,和打印時凌空部分的接駁(無重力的Printer應該解決到這問題?)。當日想到的飯盒設計如果有螺旋的接駁位,而非榫位的話,就應該未必適合3D printing。如果要推動人們的這個行為,整個設計也要考慮實用和外觀。設計一個特色的飯盒或許還容易,但要配合到餐廳的工作和用家的實用美觀,一個設計很難符合每種需要⋯⋯另外兩晚都到觀塘的工作室開會,就我們最弱的營利模式去設計活動,最後提供的服務算是面向HR的⻆度。另一方面,也簡單的寫下未來三年內按季的「現金」流向和相關活動,看著這張表,我認為經過這個準備,才會比較清楚之後要落實計劃時,有什麼先後程序上的鋪排。另外,我們想改變的是平日生活的習慣,所以都希望這星期大家親身嘗試體驗。


最後一日的決賽-以目標創業這件事就不是最後一天。大會向瑞信借場,在ICC上的寫字樓舉行。因應場地的熒幕尺寸,我們還是急急地再調整powerpoint。今次的評分方式不太一樣,是每位評審手上有不同比例的籌碼,總數十萬元,評審們以手上籌碼作評分之餘,也直接反映為每組最後的獎金。好處是可以直接反映他對該組的支持/模擬資金投資的角度;但另一方面人性上有分散投資這傾向的話,結果會趨向較為平均。相比「贏者全拿」的結果,應該誰也不會有足夠資金推動計劃,需要隊伍自身有很強的意念和力量去推動項目,以把這次獎金只視為部份資助,;但另一方面少了擔心單隊隊伍全拿後一筆過失敗的風險。這種模式在協助 "Greenovation" 和投資 "Startup" 的角度去考慮,如果我要保守地作出決策,大概現在這套也是好方法⋯⋯我們得到第二高的獎金,1st runner up。還有的是SaSa贊助的Voltra名額、香港航空機票、工匠灣會藉。

實驗
精實創業法將初創事業的作法當成一連串的實驗重新看待,每一項實驗的目的,都是為了找出一個以願景為藍圖讓企業永續經營的方法。
[關鍵概念]
- 立即實驗
- 實驗即產品
測試
「最小可行產品」與雛型產品或產品概念測試不同,它不是用來回答設計或技術上的問題,而是為了要測試重要的商業假設。
[關鍵概念]
- 品質與設計在最小可行產品中扮演的角色
評估
初創事業的任務是:第一,積極評估自己現在所在的位置,然後勇敢面對評估出來的殘忍事實;第二,設計可以學習如何將實際數字推向目標的實驗。
[關鍵概念]
- 可行指數與虛榮指數
2016年3月24日 星期四
GGC - Startup Challenge 後記:一
3月初的這兩星期很多時間都放了給GGC Challenge 密集的日程中,這篇回顧發覺也打得太長了,先放一半上來。過了「決賽日」現在的回顧,今次應該是體驗到一種類似Startup weekend的活動。當初參加的動機,因為大會的主題"Greenovation" -綠色創新是我有興趣的主題,想實際地能用自己自學的電腦知識解決一些現實問題,而且希望遇到什麼有趣、有本事的人。活動開始時,我不是帶著自己想要推行的計劃而來的。參照現在所知的startup weekend 流程去比較,GGC會經過的階段大致為:
1) 活動簡介&Workshop => 2) 分享個人Idea & 組隊 => 3) 周未的Development/Prototype & Pitching => 4) 一星期的改進 => 5) Final Pitching
1) 活動簡介&Workshop => 2) 分享個人Idea & 組隊 => 3) 周未的Development/Prototype & Pitching => 4) 一星期的改進 => 5) Final Pitching
2016年2月28日 星期日
[Math] Office Work - Single Precision Error from Decimal to Floating
電腦是以1、0表示所有資料,基本如數字也是這樣,為了在同樣容量下儲存更多或更準確的數字,便先要指定格式。例如以32Bit的單位下,如果我們想記錄「整數」,先有1 Bit用了表示正負數,餘下的31 Bit就只可以記錄$2^{31}$個數,所以32 Bit最大的正整數是$2^{31}-1 = 2147483647$。如果電腦要紀錄更大的數值,就要指定要其他的儲存容量(例如Long Integer:用多一倍的單位64Bits)或其他的儲存方式(例如Float:$1.0 \times 2^{128}$)。
以印尼银行(Bank Indonesia - 印尼的中央銀行)的印尼盾匯率為例:印行會用當日雅加達時間上午8.00-9.45銀行間同業交易的USD/IDR即期匯率,計算加權平均,然後在上午10.00公佈該這個參考價-雅加達銀行同業即期匯率(JISDOR),和現時22種貨幣的參考匯率,發佈的數字只有買入價、賣出價,並沒有中間價。
要知道一般大眾看的就是中間價。談到日元歐元下跌又是旅行良機時,你不會分別說買入賣出價是多少。某數據供應商亦合理地有提供中間價 ( =(買入+賣出)/2 )。只是,數據商預設準確至2個小數位(2 d.p.) ,當我們留意這個數據的準確性時,卻偶然出現細小的誤差,例如:

以印尼银行(Bank Indonesia - 印尼的中央銀行)的印尼盾匯率為例:印行會用當日雅加達時間上午8.00-9.45銀行間同業交易的USD/IDR即期匯率,計算加權平均,然後在上午10.00公佈該這個參考價-雅加達銀行同業即期匯率(JISDOR),和現時22種貨幣的參考匯率,發佈的數字只有買入價、賣出價,並沒有中間價。
要知道一般大眾看的就是中間價。談到日元歐元下跌又是旅行良機時,你不會分別說買入賣出價是多少。某數據供應商亦合理地有提供中間價 ( =(買入+賣出)/2 )。只是,數據商預設準確至2個小數位(2 d.p.) ,當我們留意這個數據的準確性時,卻偶然出現細小的誤差,例如:

2016年2月20日 星期六
[Math] Office Work - 從編排更表到Hungarian Algorithm
因為會處理歐美收市和亞洲收市,所以我這組人的繁忙時間是清早和晚上兩端,需要有輪班制,工作分早晚兩更,據英文堂所學這種工作時間有個形容詞是antisocial hour, 人手足夠時就可以讓同事返九點左右的正常時間。編更上如何令大家滿意,這問題幾似數學Operational Research / Graph Theory中的 Matching problem。大概最近FB見到恆隆同伯賴段片,數學應用的頭腦靈活過來,想到還是可以用典型的Hungarian Algorithm。這演算法所處理的情況是:假設有n個任務需要分派給n個人,每人要完成各個任務都有某個成本,問如何編配任務才能讓總成本最少。
例如成員 i 要處理任務 j 的成本是cij,這些成本可以寫成矩陣C表示。例如第一個人p1處理任務一task1要成本1, p1 處理 task2 要成本5, p1 處理 task3 要成本3;分派方法可以寫成矩陣A,這簡單例子的最佳分配可以直觀得知如下, 總成本為6。而Hungarian Algorithm 的步驟是這樣,大致有以下程序:(一)將所有數值減去該行最小的數,然後再將所有數值減去該列最小的數,今每行、列都有零存在。(二)[Trial and Error] 找出一個"Independent zero"的組合,用最少條線穿過所有零。(三)如果剛好存在於n條線上,該"Independent zero"組合就可以得出答案;如果只需少過n條線,修改矩陣重覆步驟二。
$$
C=\begin{bmatrix}
1 & 5 & 3 \\
4 & 2 & 8 \\
7 & 9 & 3 \end{bmatrix},
A=\begin{bmatrix}
1 & 0 & 0 \\
0 & 1 & 0 \\
0 & 0 & 1 \end{bmatrix}
$$
例如成員 i 要處理任務 j 的成本是cij,這些成本可以寫成矩陣C表示。例如第一個人p1處理任務一task1要成本1, p1 處理 task2 要成本5, p1 處理 task3 要成本3;分派方法可以寫成矩陣A,這簡單例子的最佳分配可以直觀得知如下, 總成本為6。而Hungarian Algorithm 的步驟是這樣,大致有以下程序:(一)將所有數值減去該行最小的數,然後再將所有數值減去該列最小的數,今每行、列都有零存在。(二)[Trial and Error] 找出一個"Independent zero"的組合,用最少條線穿過所有零。(三)如果剛好存在於n條線上,該"Independent zero"組合就可以得出答案;如果只需少過n條線,修改矩陣重覆步驟二。
$$
C=\begin{bmatrix}
1 & 5 & 3 \\
4 & 2 & 8 \\
7 & 9 & 3 \end{bmatrix},
A=\begin{bmatrix}
1 & 0 & 0 \\
0 & 1 & 0 \\
0 & 0 & 1 \end{bmatrix}
$$
2016年2月10日 星期三
北區 : 聯和墟-馬屎埔-華山-坪輋/坪洋
同焜哥定好新年假期由粉嶺出發,試行我們的北區計劃有什麼地方可以去/可以寫。最緊要係仲會帶定營帳睡袋嘗試今晚上華山露營。
上午大約10.30在粉嶺火車站出發,先到聯和墟的茶餐廳食個早餐。聯和街一帶有不少街坊食店,舊街市入面的小店地圖都有介紹。我地隨便選了間仍有早餐的光顧。第一站先往粉嶺聖若瑟堂參觀 (http://www.catholicheritage.org.hk/tc/catholic_building/st_joseph_church/index.htm 檔案室內有些1953年6月7日報章
紀錄當時的模型) 這教堂1953年落成,奉聖若瑟為主保,以工匠的手藝養活家人的聖若瑟,想到附近的手作村。入口前的銅牌寫著粉嶺聖若瑟堂是三級歷史建築物。不過有更耐歷史的是走廊上的三個大鐘,大鐘是戰時的九龍城聖方濟堂遺物。九龍城一八六零年代在當時海旁已經設有傳教站,並在一八六九年建立的聖方濟各沙勿略堂(記念十六世紀到東南亞開教的耶穌會士聖方濟各沙勿略),到後來一九三零年代興建機場,政府以換地形式在附近批出土重建,資助人亦將聖堂改名為聖五傷方濟各堂。到日治時期日軍為擴展機場,教堂再被拆去(現在最近原址附近的聖方濟各堂己經要數深水埗區) ,另一個當時為此而被炸毀的還有沙中綫土瓜灣站發現的聖山遺址。 回到現在,粉嶺聖若瑟堂是一些新人行婚禮的心水地點。右後方露出一角的是新鴻基2014年落成的單幢樓項目──瓏山一號。
新鴻基地產即將推出粉嶺樓路項目──瓏山一號
新鴻基地產即將推出粉嶺樓路項目──瓏山一號

2016年1月29日 星期五
Glocal Greenovation Challenge Application
近兩星期看到到Voltra有這個活動 http://www.glocalgreenovation.com/ ,雖然自己已經過了對MT Program有興趣的年紀,但對Makerbay和 可以遇到什麼有才能的人就很感興趣。還有,像是那些IT界的Hackathon是怎樣的感覺?發揮自己的興趣和想法,在工作以外再創業是可行的嗎?
反正這個Self-Introdcution Profile要放上網再用遞交連結,一併放在這裡。
^^ -----------------------------------(我是分隔線)----------------------------------- ^^
2016年1月15日 星期五
[Python] Facebook page 的 Like 與 Crawling
網上找Facebook上做Web crawling 的方法,記得之前試過某Coursera教Twitter上的Crawling,用到服務本身提供的API和Authentication Token。Twitter/Google map的教學的都有Coursera上的課堂,但FB提供的只有網上找到零碎的教學,當時是一個外國Vlogger like Emma Watson posts的Script。試明白後把這段code貯起來做參考,想不到這星期剛好有用得上的時候。用到以下的第三方SDK, 安裝後用 import facebook 載入。
Python 的facebook SDK: https://github.com/pythonforfacebook/facebook-sdk
更多的Facebook SDK: https://developers.facebook.com/docs/apis-and-sdks
了解背後的FB Graph API的用法: https://developers.facebook.com/docs/graph-api/overview
找取 & like page 的post:
- 'toke here' 的token 可以在GRAPH Explorer中得到, (Keep it secret!!)
- "ejmonthly" 是信報財經月刊的Facebook name, 看網址就會找到了。
對於ejmonthly 這個profile, 當用get_connections連繫上它的posts資料, 就可以對它的資料內容
資料做事了。抓取內容時,其本上是一層層的dictionary 結構。做動作時就用到sdk內的function, 如put_object() 去對某個post 給like。
訂閱:
文章 (Atom)